SHTns can efficiently use a GPU to perform spherical harmonic transforms. Supported GPUs include nvidia Kepler, Pascal, Volta, Ampere, as well as AMD MI100 and MI200 series.
There are two ways to use GPUs with SHTns:
- automatic off-loading where the GPU is used transparently (not much to change in your code) and SHTns handles all the data transfers between GPU and CPU memory.
- transforming data residing already on the GPU , using specific functions (prefixed by cu_).
In all cases, you must first configure SHTns to use cuda (for nvidia devices) or hip (for AMD devices):
For AMD gpus, replace --enable-cuda by --enable-hip above. Optionally, you can specify which GPU you are targetting with
or
for instance.
Automatic off-loading
Auto-offloading is simple to use, but will benefit only to transforms large enough to amortize the cost of memory transfers between CPU ans GPU. What "large enough" means depend on details of your system, but gains can reasonably be expected for Lmax > 1000. To enable automatic off-loading (if possible and if faster), simply add SHT_ALLOW_GPU to the shtns_type argument of shtns_set_grid_auto.
If no GPU is found, the transforms will be performed on CPU instead.
- Warning
- the transforms are no more guaranteed to be thread-safe, because the GPU ones are not. Please make sure to use different shtns configs (or plans) if you want to call transform functions from multiple threads. See also Cloning shtns configs below.
- Ressources are allocated on the current (or default) device for each plan. In case multiple devices are used, the user is responsible for setting the correct device before calling SHTns.
For best performance, you must also allocate memory for your spatial and spectral arrays using shtns_malloc and subsequently free it with shtns_free. This way, so-called "pinned" memory is used when cuda is enabled, allowing faster data transfer between host and device.
If you are not calling transform functions from multiple threads, you have nothing more to do.
Cloning shtns configs
The function cushtns_clone creates a new identical configuration, but with new GPU ressources (temporary buffers, streams, ...). The user can give custom cuda streams or let shtns set his own (by passing 0 for each cuda stream).
The resulting shtns config can be used concurently with the original one. Repeat the cloning for each concurrent thread.
On-device transforms
On-device transforms are declared in shtns_cuda.h (for both nvidia and AMD gpu). Basically the regular transform functions have been prefixed by cu_ to indicate that they work on device memory. See GPU transforms..
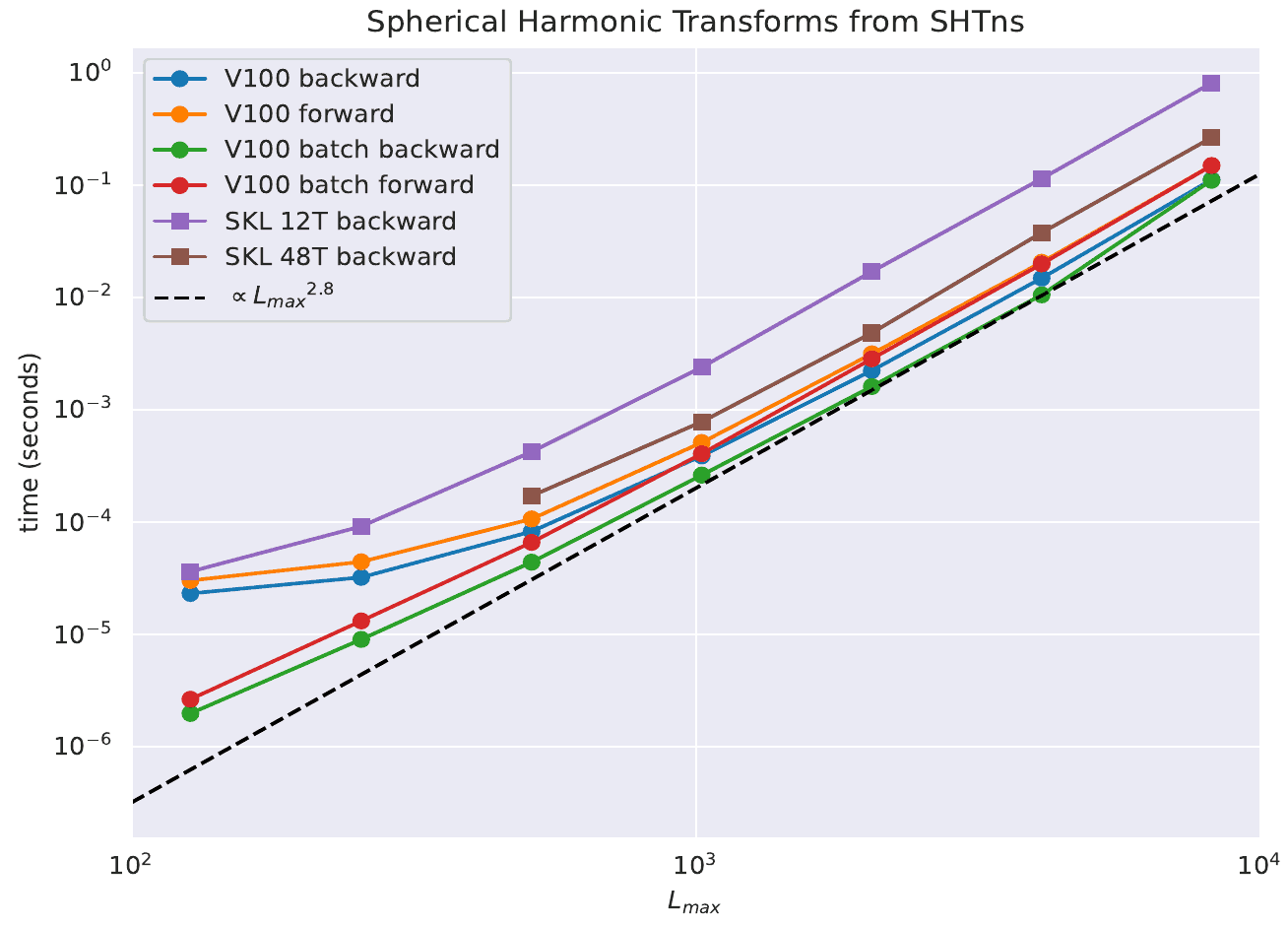
These on-device transforms are usually much faster than CPU transforms (typically 1 GPU performs like 100 CPU cores) provided enough parallelism can be exposed. This means for a single transform Lmax > 200, but if many transforms can be grouped together (see shtns_set_batch), Lmax>63 is enough.
It is also possible to use cuda unified memory allocated by cudaMallocManaged(), but this has not been tested extensively.
As for the automatic off-loading, the GPU transforms are NOT thread-safe and the same shtns config should never been used from simultaneous CPU threads. To help the user to create clones of the same shtns config, cloning functions for GPU transforms have been added.
Initialization of on-device GPU transforms
One a shtns config has been setup normally by calling shtns_create followed by shtns_set_grid or shtns_set_grid_auto, one simply calls cushtns_init_gpu to prepare the gpu for on-device transforms.
- Warning
- Initialized that way, auto-offload transforms will NOT work (temporary buffers on GPU not allocated) but less GPU memory is used. On the contrary, on-device transforms will work also when auto-offload was allowed (at the expense of a larger memory footprint).
Performance of scalar transforms on GPU (nvidia V100) and CPU (intel SKL) is given in the following plot (excluding memory transfers). The benefit of batching is evident. See also the conference poster Efficient spherical harmonic transforms on GPU.
Generated on Mon Oct 7 2024 17:40:44 for SHTns by